


What E-E-A-T actually means in 2026
E-E-A-T is a verification architecture, not a content checklist. Google’s systems are trained to detect trust signals across four dimensions simultaneously, and trust is the dimension that overrides all others. A page can demonstrate exceptional experience, deep expertise, and strong authoritativeness, and still receive low E-E-A-T if the trust signals are absent or unverifiable.
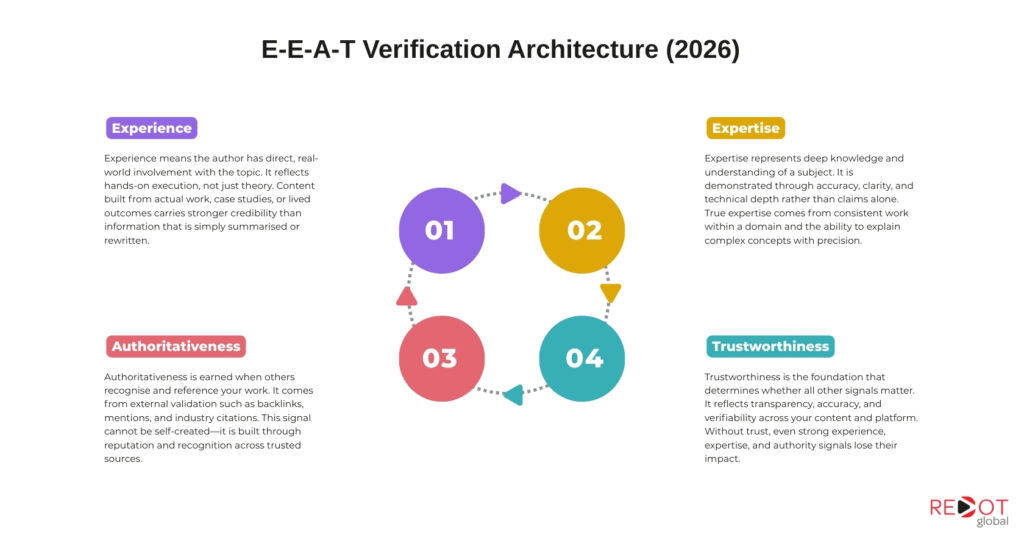
The four components have precise definitions that are often misunderstood in practice.
Experience means you have done it. The author has first-hand, lived involvement with the topic they are writing about. An SEO strategist writing about Google Ads Quality Score has experience. A content writer summarising Google documentation does not. Google added Experience to the framework in December 2022, within weeks of ChatGPT’s public release, specifically because AI systems can produce expertise but cannot produce genuine first-hand experience.
Expertise means you know it. Demonstrable knowledge through credentials, education, professional track record, or sustained depth of coverage in a specific domain. Expertise is shown through the quality and accuracy of the content itself, not just claimed through a bio.
Authoritativeness means others recognise it. External recognition from credible, independent sources. Backlinks, press mentions, industry citations, and community references all contribute. Authoritativeness cannot be self-declared. It is conferred by third parties whose own authority Google has established.
Trustworthiness means it is accurate and transparent. Clear authorship, verifiable sourcing, secure site infrastructure, transparent editorial processes, and honest representation of commercial relationships. Google’s Search Quality Rater Guidelines state explicitly: “Trust is the most important member of the E-E-A-T family because untrustworthy pages have low E-E-A-T no matter how Experienced, Expert, or Authoritative they may seem.”
The critical correction to a widespread misunderstanding: E-E-A-T is not a score. Google does not assign an E-E-A-T number to pages or domains. It is a framework that Google’s systems are trained to evaluate through multiple underlying signals. You cannot improve your E-E-A-T by adding an author bio to a single page. You build it through consistent, verifiable behaviour across your entire content and entity presence over time.
The Beyond the Keyword pillar guide introduces E-E-A-T as the fourth dimension of modern SEO alongside technical infrastructure, information gain, and user-intent alignment. This post covers the full implementation layer: how to build E-E-A-T signals that Google and AI systems can actually verify.
How Google verifies E-E-A-T signals
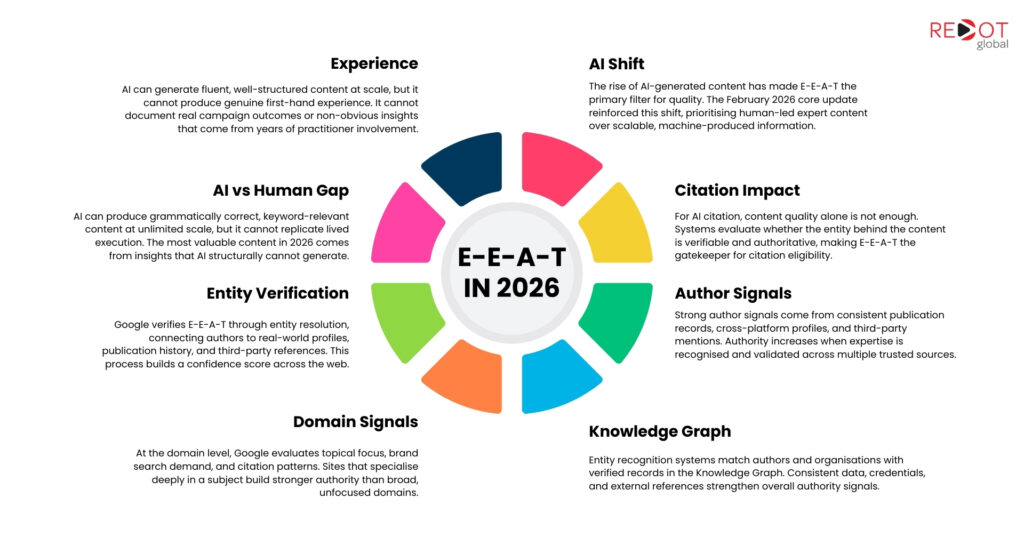
Google verifies E-E-A-T through entity resolution, not page evaluation. It connects an author’s name on your site to the same person’s LinkedIn profile, publication history, conference speaking records, and third-party mentions to build a confidence score for that entity. The process is not manual. It is algorithmic, continuous, and operates across the entire web.
Entity resolution is the mechanism. Named entity recognition identifies people, organisations, and topics mentioned in content. Entity reconciliation then matches those identified entities against known records in the Knowledge Graph and Knowledge Vault. Google looks for a match between the author named on your site and a verified professional record elsewhere on the web. If it finds a consistent publication history, relevant credentials, and third-party mentions in the right topic domain, the author’s authority score increases.
What Google checks at the author level
Consistent publication record. Multiple pieces of published content under the same name, ideally across multiple authoritative domains, creates a verifiable pattern. A person who has published once is a thin entity. A person with a sustained publication record across a specific topic domain is a recognised expert entity.
Cross-platform profile links. Google’s Search Central documentation on creating helpful content asks explicitly: “Do bylines lead to further information about the author or authors involved, giving background about them and the areas they write about?” The answer should be yes, with links from the author bio to LinkedIn, professional directory profiles, and any publication history.
Third-party mentions with named area of expertise. Press coverage, conference speaking records, academic or industry publications, and professional directory listings that reference the author entity by name and connect them to a verifiable area of expertise are the strongest authority signals. These are signals that Google can verify independently without relying on what the author claims about themselves.
Credentials that match the topic domain. An article about Google Ads performance carrying authorship from a Google-certified paid search specialist receives stronger E-E-A-T signals than the same article from a generalist content writer. The credential must match the topic. Google’s Agent Rank patent describes this as topic-specific authority. An author can have high authority in one domain and no authority in another. Google distinguishes between them.
What Google checks at the domain level
Topical focus score. Google evaluates how consistently a domain covers a specific subject area versus publishing broadly across unrelated topics. A domain that consistently publishes high-quality content on technical SEO builds stronger topical authority than a domain that publishes on SEO, lifestyle, finance, and entertainment with equal frequency.
Brand search volume. When users search for a brand name directly, it signals to Google that the brand has an established audience who trusts it enough to seek it out specifically. Brand search volume is an indirect E-E-A-T signal that reflects real-world recognition.
Knowledge Graph entity recognition. Organisations and individual experts who are recognised entities in Google’s Knowledge Graph receive stronger authority weighting. Getting into the Knowledge Graph requires verifiable entity connections: business registration, consistent NAP data, partner directory listings, and third-party references that confirm the entity’s existence and area of expertise.
Third-party citation patterns. How frequently do authoritative external sources reference your brand, your content, and your authors? This is the off-page dimension of E-E-A-T that most content strategies underinvest in.
Building verifiable author entity authority from scratch
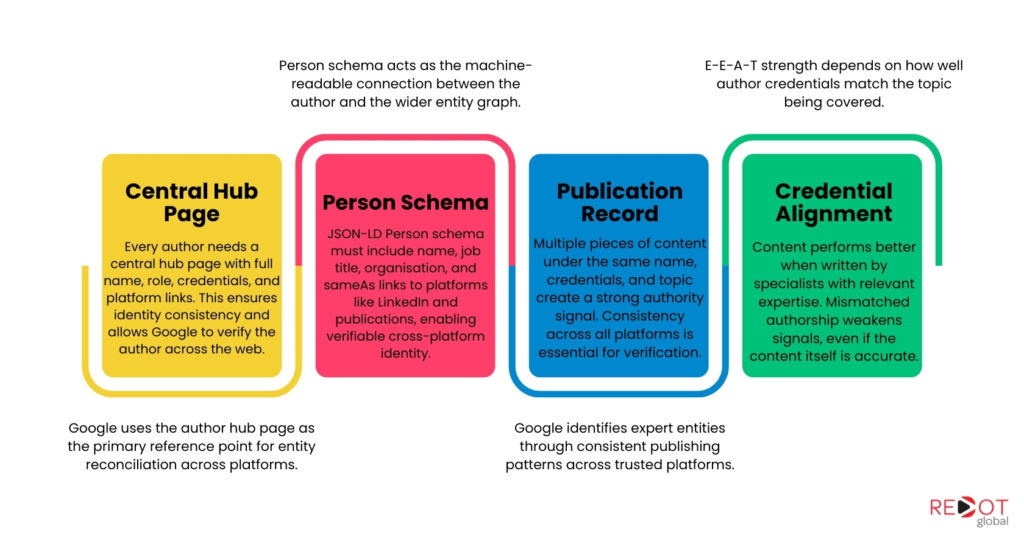
A verified author entity requires four components working together: a central hub page, a consistent publication record, machine-readable schema, and cross-platform identity anchors. Without all four, Google cannot resolve the entity with confidence. Partial implementation produces partial results.
The central hub page
Every author needs one page that functions as the entity anchor point. This is typically the author bio page on the company website. It must contain the author’s full name exactly as it appears on all publications, current role and organisation with a verifiable connection, credentials directly relevant to the topic domain they write about, links to every platform where the author publishes, and a professional photograph that matches the author’s profile images on external platforms.
The hub page is what Google uses as the reference point for entity reconciliation. When it sees a name on a blog post, it checks whether a hub page exists. It then checks whether that hub page links to a consistent set of external profiles, and whether those external profiles reference the same credentials and topic focus. Consistency across all of these is the signal that the author identity is genuine and can be verified independently.
Person schema with sameAs chain
The technical mechanism that connects the author hub page to the broader entity graph is JSON-LD Person schema markup. This is not optional. It is the machine-readable instruction to Google on how to connect the author entity across platforms.
Person schema must include at minimum: name matching the byline exactly, jobTitle reflecting the role at the publishing organisation, worksFor as an Organisation entity with its own schema, and a sameAs array linking to LinkedIn, any industry publication profiles, Google Scholar if applicable, and any professional directory listings. Each sameAs URL creates a verifiable connection that Google can independently check.
The Schema.org Person markup documentation defines the full property set. For E-E-A-T purposes, the sameAs array is the most critical property because it creates the verifiable cross-platform identity connections that entity resolution depends on.
Consistent publication record
Multiple pieces of content published under the same author name, with the same credentials, on the same topic domain, creates the verifiable publication pattern that Google’s systems identify as a genuine expert entity. A single byline is a thin signal. A sustained publication record is a strong one.
Guest posts on industry publications, contributions to recognised platforms, and consistent bylines on the company blog all contribute. The key requirement is consistency: same name, same credentials, same topic focus across all publishing venues. Inconsistency in how an author is represented across platforms weakens the entity resolution signal.
Credential-topic alignment
This is the most underappreciated E-E-A-T implementation requirement. The credential on the author bio must match the topic of the post. An article about technical SEO carrying authorship from a Google-certified SEO strategist with a documented ranking track record receives strong E-E-A-T signals. The same article carrying authorship from a marketing manager with no SEO credentials receives weak signals, regardless of how accurate the content is.
For Redot Global, this means technical posts about server architecture, Core Web Vitals, and crawl budget should carry authorship from the engineers and infrastructure specialists who have the certifications and operational experience in those domains. SEO strategy posts should carry authorship from the strategists whose track record is in that area. One author bio template applied to all posts regardless of topic is a missed E-E-A-T opportunity.
Editorial standards as an institutional trust signal
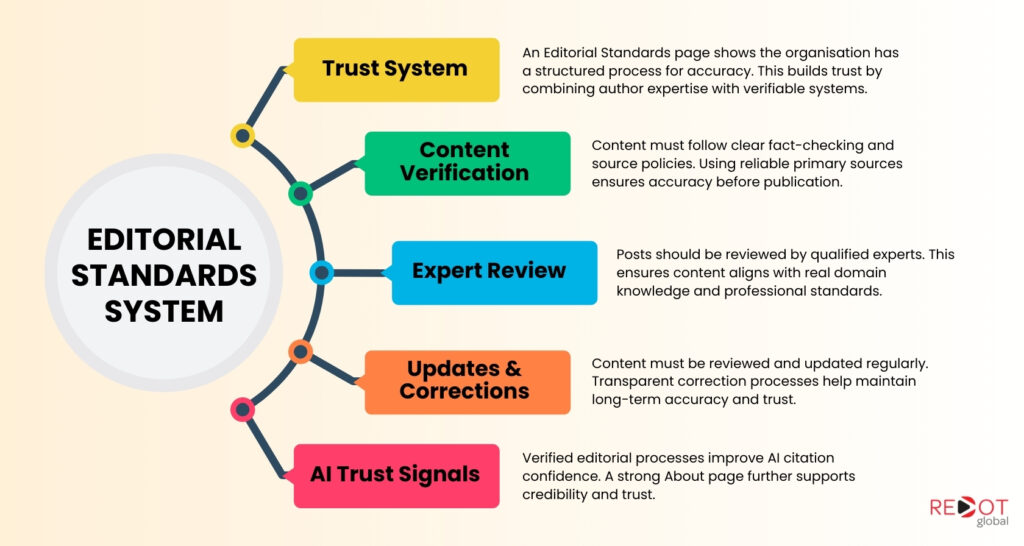
An Editorial Standards page signals to both Google’s quality raters and AI systems that the organisation behind the content has a systematic process for ensuring accuracy, not just individual expertise. Individual author authority and institutional editorial standards work as complementary layers. Strong authors on a site with no visible editorial process are less trustworthy than strong authors on a site with published, verifiable editorial standards.
What an Editorial Standards page must contain to function as an E-E-A-T signal:
- Fact-checking process: how claims are verified before publication, what sources are considered acceptable, and whether external sources are checked against primary documentation.
- Source verification policy: which types of sources are cited, how to handle conflicting sources, and what constitutes a verifiable primary source versus a secondary aggregation.
- Expert review protocol: whether posts are reviewed by subject matter experts before publication, who those reviewers are, and what their credentials are in the relevant domain.
- Update frequency commitment: how often published content is reviewed for accuracy, how material changes are indicated to readers, and what triggers a full revision versus a minor update.
- Correction policy: how factual errors are handled after publication, whether corrections are noted inline or in a separate corrections log, and how readers can report inaccuracies.
For AI citation specifically, publishing organisations with verifiable editorial processes receive higher citation confidence from AI retrieval systems than organisations without them. A brand that can demonstrate institutional processes for accuracy is more trustworthy as a citation source than a brand that relies solely on individual author expertise.
The About page is the companion to the Editorial Standards page. Google’s quality raters are specifically trained to look at a site’s About page when evaluating trustworthiness. It should clearly explain who runs the site, what the site covers, why users should trust it, contact information, and business registration or accreditation references. A one-paragraph About page is not sufficient for a business publishing content that influences commercial decisions.
The platforms that carry the most E-E-A-T weight for Singapore technology businesses
Major news and media publications. For Singapore businesses, the Business Times, The Straits Times, and regional technology publications including e27 and Tech in Asia carry significant weight in both traditional E-E-A-T evaluation and AI citation patterns. Coverage in these publications creates verifiable entity connections that Google can find in its training data and live index.
Google Partner and AWS Partner directories. Industry certification and partner directory listings create verifiable entity connections between your brand and established institutions. Google Partner status, AWS Network Partner listing, and similar accreditation references are signals that AI systems can verify directly against official partner databases.
Clutch and G2 structured review platforms. Review platforms with structured data are increasingly reflected in AI citation patterns for commercial queries. A Clutch profile with specific, named service reviews and verifiable client outcomes contributes to the entity verification chain for queries about agency selection and service quality.
Reddit and community platforms. Reddit remains the most cited domain across LLMs relative to its traditional SEO authority, with LinkedIn rising to second position as of early 2026, ahead of Wikipedia and every major news publisher.
A thread on r/singapore or r/SEO that mentions your brand in a specific, positive context contributes to entity recognition in ways that traditional link building does not. Community mentions are perceived as independent and unsponsored, which is why they carry outsized trust weight.
How to build a digital PR programme specifically for E-E-A-T
Target publications that AI training datasets weight heavily rather than publications chosen purely for domain authority. For Singapore businesses this means regional technology and business publications rather than generic high-DA directories. Create genuinely citable content: original research, documented client outcomes with named metrics, and expert commentary on industry developments that journalists and publications want to reference. Document client outcomes that can be named and verified, because proprietary data with named entities and specific metrics is the most citable form of content both for traditional press and for AI retrieval systems.
Redot’s own E-E-A-T signals as a worked example: Google Partner certification and AWS Network Partner status create verifiable institutional connections. Named client case studies with documented outcomes, published on the website and referenced in the citation table in the Citation Economy guide, create proprietary data that no competitor can replicate. Singapore headquarters with verified business registration and consistent NAP data across directories confirms the organisation entity.
E-E-A-T for YMYL content
If your business publishes content that influences financial, legal, health, or civic decisions, Google applies its highest E-E-A-T standard. Most Singapore B2B technology businesses are publishing YMYL-adjacent content without recognising it, and the consequences for insufficient E-E-A-T signals in these categories are among the most consistent ranking penalties in Google’s quality evaluation system.

The current YMYL categories after the September 2025 update
The Google Search Quality Rater Guidelines updated September 11, 2025 define four YMYL categories:
- YMYL Health or Safety: Topics that could harm mental, physical, and emotional health, or any form of safety. This includes symptoms, treatments, medications, mental health, nutrition, emergency procedures, and product safety.
- YMYL Financial Security: Topics that could damage a person’s ability to support themselves and their families. This includes investments, mortgages, loans, taxes, retirement planning, and any content that influences money management decisions.
- YMYL Government, Civics and Society (expanded September 2025): Topics that could negatively impact groups of people, issues of public interest, trust in public institutions, election and voting information, and any other informational topics about government, civics or society that impact people’s lives. This category was explicitly expanded in the September 2025 update.
- YMYL Other: Topics that could hurt people or negatively impact welfare or well-being of society. This includes legal topics, content about groups of people, and any topic where inaccuracy could cause harm outside the three categories above.
Why B2B technology businesses are often publishing YMYL-adjacent content without realising it
Content about business software investment decisions falls into financial advice territory. Content about cloud infrastructure security and data compliance falls into safety and legal territory. Content about Singapore government digital initiatives and regulatory requirements now falls into the Government, Civics and Society category after the September 2025 update.
A Singapore business publishing a guide on PDPA compliance, MAS digital banking regulations, or government grant eligibility is publishing YMYL content. If that content lacks verifiable author credentials, formal expert review, and transparent sourcing, it faces the most rigorous quality rater evaluation and the most consistent ranking penalties when E-E-A-T signals are insufficient.
The practical implication is straightforward: audit every piece of content on your site against the YMYL categories. For any content that falls into or near these categories, apply the higher E-E-A-T standard: formal credentials for the author in the relevant domain, external expert review of published claims, transparent sourcing for all statistics and recommendations, and clear disclosure of any commercial relationships that could create a conflict of interest.
How E-E-A-T verification differs between Google rankings and AI citations
Traditional Google rankings evaluate E-E-A-T as a domain and author level signal applied broadly across a site’s content. AI citation systems evaluate E-E-A-T at the individual page level, in real time, against the specific query being answered. Understanding this distinction prevents the common mistake of treating E-E-A-T as a site-level investment rather than a per-page requirement.
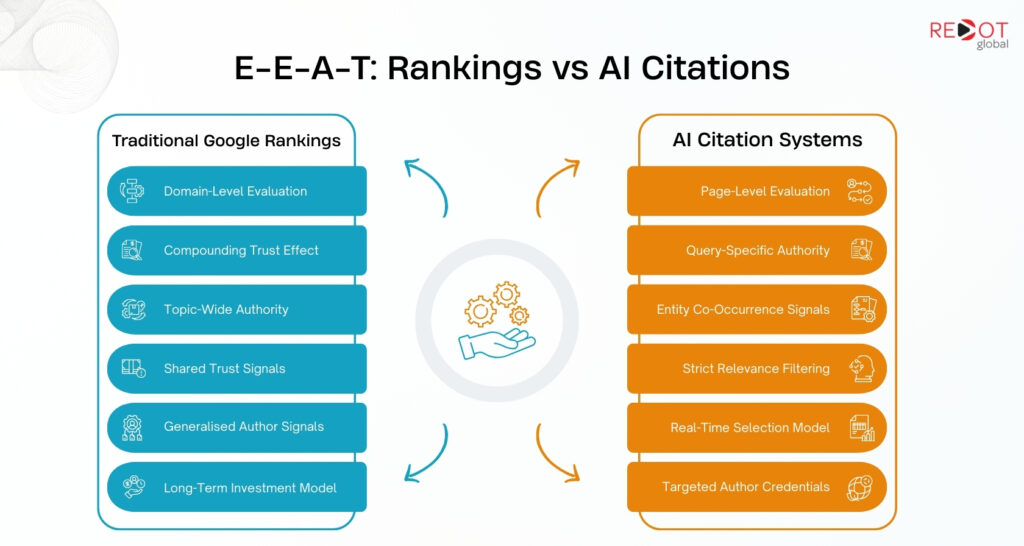
How E-E-A-T operates in traditional Google rankings
In traditional search, E-E-A-T builds domain-level topical authority over time. A consistently publishing expert author raises the E-E-A-T floor for every page on the domain. A domain with strong author entities, consistent topic focus, institutional editorial standards, and third-party validation receives a baseline trust advantage that benefits all content, including pages that individually might have thinner E-E-A-T signals.
This is the compounding effect of E-E-A-T investment. Early investment in author entity building, editorial infrastructure, and third-party validation creates a trust asset that appreciates with every new piece of published content. The information gain content strategy guide covers how information gain and E-E-A-T reinforce each other at the content level: high information gain content with verifiable author credentials produces the strongest combination of ranking and citation signals.
How E-E-A-T operates in AI citation systems
In AI retrieval, E-E-A-T is evaluated per query. A page can have strong domain-level E-E-A-T and still be excluded from a specific AI citation if the author credentials do not match the specific topic of the query being answered. If a user asks ChatGPT about Core Web Vitals optimisation and your site’s technical SEO content carries authorship from a marketing manager rather than a certified SEO engineer, the page receives a lower authority weighting for that specific query even if the domain has strong overall E-E-A-T.
Entity co-occurrence is the AI-specific mechanism. When an author entity is consistently associated with a specific topic across multiple platforms, AI systems build a high-confidence link between that author and that domain. This is why consistent topic focus in authorship matters as much as credential verification. Consider an author who writes about technical SEO on your site, is listed as an SEO specialist on LinkedIn, has contributed to industry forums like Search Engine Journal and Search Engine Roundtable, and is referenced in Google Partner programme documentation. That pattern of co-occurrence signals genuine, verifiable expertise to AI retrieval systems.
The practical implication for every page on your site: the author bio must specifically name the credentials that make this author authoritative for this specific post’s topic. A generalised bio that says “digital marketing professional with ten years of experience” is a weaker E-E-A-T signal for a technical SEO post than a targeted bio that says “Google-certified SEO strategist with seven years of technical SEO and infrastructure optimisation experience across Singapore, Canada, and Germany.”

Head of Digital Marketing, Redot Global
Kasun Asiri is a Digital Marketing Strategist with over 15 years of experience delivering high-impact digital growth initiatives across global markets. At Redot Global, he plays a key role in planning and executing performance-driven campaigns for international brands, consistently achieving measurable results through advanced SEO, Google Ads, and integrated digital visibility strategies. With deep expertise at the intersection of marketing, technology, and data, he specialises in building scalable growth systems powered by data science and AI-driven automation, transforming traditional marketing into efficient, data-driven frameworks designed to drive sustainable business growth. His work is defined by analytical thinking, strategic execution, and a commitment to delivering performance-focused solutions that align with business goals and long-term success.


