


What is information gain in SEO?

Information gain is the measure of genuinely new, unique, and verifiable insight your content adds to the web. It is not a measure of length, keyword density, or how comprehensively a topic is covered in general terms. It is a measure of whether your content tells Google and AI systems something they cannot already find expressed in identical or near-identical form across thousands of other pages.
Google’s systems have evaluated information gain as a quality signal since the Helpful Content Update era. Google’s February 2026 core update explicitly increased the weighting of information gain as a ranking signal, with sites publishing original, expert-driven content gaining visibility while those producing aggregated or AI-generated content without meaningful human oversight saw measurable ranking losses.
The mechanism is straightforward. Google indexes the web at scale. When a new piece of content arrives, its systems compare it against the existing corpus. Content that introduces new data, new analysis, new first-person observations, or new connections between established ideas scores high on information gain. Content that reorganises what already exists scores low, regardless of how well it is written.
Understanding information gain fully requires connecting it to the infrastructure and citation layers that determine whether high-quality content can actually rank and get cited. The Beyond the Keyword pillar guide establishes the full framework. The Inefficiency Tax post covers how infrastructure decisions affect whether Google can access and evaluate your content at all. The Citation Economy post covers how GEO, AEO, and SGE determine citation selection. This post covers the content layer: what information gain is, how to produce it, and how to structure it for both Google and AI retrieval systems.
How information gain affects Google rankings and AI citations differently
Information gain is not exclusively an AI citation concept. It is a traditional Google ranking mechanism that has been reinforced by every major algorithm update since 2022. Understanding how it operates differently across traditional search and AI retrieval helps you optimise for both outcomes simultaneously rather than treating them as separate tracks.
How information gain drives traditional Google rankings
Google’s traditional ranking systems evaluate information gain through four compounding mechanisms, each of which operates independently of AI citation selection.
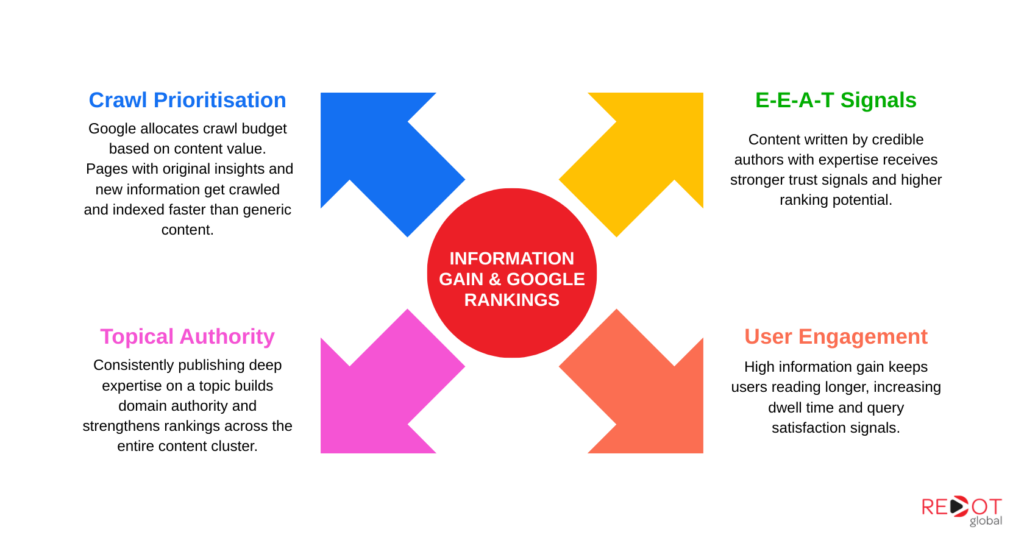
Crawl prioritisation and indexation speed. Google allocates a crawl budget to every domain, the number of URLs it is willing to crawl within a given window. According to Google’s crawl budget documentation, pages may not appear in search results even if crawled, if there is not sufficient value or user demand for the content. High information gain content is perceived as higher value, which means Googlebot allocates more crawl frequency to it. A page that adds nothing new to the web gets crawled less often, indexed more slowly, and surfaced less reliably than a page that adds genuinely original insight. For competitive businesses publishing time-sensitive analysis or client results, this crawl prioritisation gap directly affects how quickly new content becomes visible in organic search.
E-E-A-T scoring at the page and author level. Google’s E-E-A-T framework, covering Experience, Expertise, Authoritativeness, and Trustworthiness, is essentially information gain evaluated at the author and domain level rather than the content level alone. A page written by a named author with a verifiable publication history in the relevant domain receives stronger E-E-A-T signals than an anonymously published page, even if both pages contain the same content. The February 2026 core update reinforced this directly by rewarding sites with named authors and verifiable credentials while penalising anonymous content regardless of quality. Information gain and E-E-A-T are not separate requirements. They are the same requirement measured at different scales.
The full E-E-A-T implementation framework, covering author entity building, Person schema, editorial standards, and YMYL compliance, is covered in our E-E-A-T authority guide.
User engagement signals as downstream confirmation. When content contains genuine information gain, readers stay longer, return more frequently, and do not immediately return to Google to search again, a behaviour Google interprets as query satisfaction. These engagement signals, including dwell time, return visit rate, and low pogo-sticking, are downstream consequences of high information gain content. Google’s systems use them as confirmation signals that reinforce initial ranking decisions. Generic content that restates what readers already know produces the opposite pattern: readers scan briefly, find nothing new, and leave. Google’s systems read that pattern as a signal that the page did not satisfy the query.
Topical authority at the domain level. Google evaluates topical authority not just at the page level but across an entire content cluster. A domain that consistently publishes high information gain content on a specific topic builds what Google’s systems interpret as genuine subject matter expertise. This cluster-level authority signal compounds over time: each new piece of high information gain content reinforces the authority of every existing piece on the same topic. Generic content published at volume has the opposite effect, diluting topical authority by signalling to Google that the domain publishes broadly rather than deeply.
What are the five signals of high information gain content?
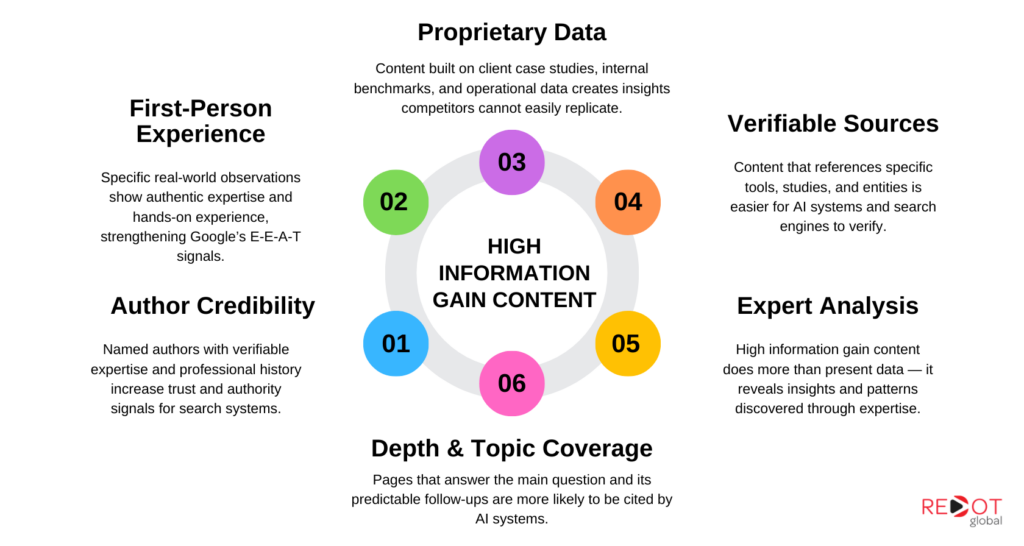
Not all original content generates equal information gain. The following five signals are the most consistently rewarded by both Google’s ranking systems and AI retrieval evaluation.
1. Proprietary data and original research
Content built on data that only you possess cannot be replicated. Client case studies with specific outcomes, internal benchmark data from real projects, and original analysis of your own operational experience all qualify.

How to structure content for AI extraction
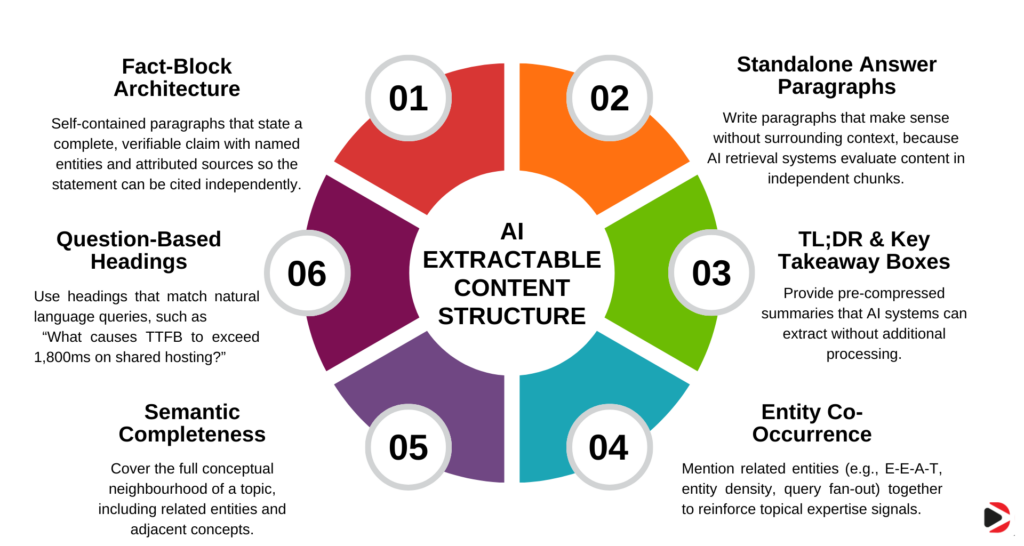
Information gain without structural accessibility is wasted. A page can contain genuinely original insights and still receive zero AI citations if those insights are not structured in a way that AI retrieval systems can extract. The following structural principles apply directly to citation eligibility.
Fact-block architecture
A fact-block is a self-contained paragraph that makes a complete, citable claim without requiring surrounding context to be understood. It names a specific entity, states a specific finding, and attributes it to a verifiable source. Every section of a high-information-gain post should contain at least one fact-block that would make complete sense if extracted and presented as a standalone citation in an AI-generated answer.
A fact-block that cites a specific outcome, names the tool or system involved, and attributes it to a verified source is extractable. A paragraph that says ‘improving your website speed will help your rankings’ is not. The difference is specificity, attribution, and self-containment.
Standalone answer paragraphs
Standalone answer paragraphs are written with the assumption that they will be read in isolation. They do not reference ‘as mentioned above’ or assume the reader has the preceding section in memory. AI retrieval systems chunk content into segments and evaluate each chunk independently. Paragraphs that depend on context established elsewhere in the post score lower on extractability.
Question-based headings
H2 and H3 headings phrased as the actual question a user would ask align directly with conversational query patterns. A heading like ‘What causes TTFB to exceed 1,800ms on shared hosting?’ tells the retrieval algorithm exactly what the following content answers. A heading like ‘Server Performance Considerations’ does not. The more precisely a heading matches a natural language query, the higher its citation eligibility.
TL;DR sections and key takeaway boxes
Pre-compressed summaries are among the most frequently extracted content elements in AI Overviews. They present information in a format the AI does not need to further condense, which reduces the processing required for citation and increases the probability of selection. Every post over 2,000 words should include a key takeaway box positioned at the top of the content, not the bottom.
Semantic completeness as a citation signal
Semantic SEO is the practice of building content around conceptual relationships, not just keywords. In the context of information gain and AI citation, semantic completeness is the degree to which a page addresses the full conceptual neighbourhood of its primary topic. It is one of the most underestimated citation multipliers in content strategy.
AI retrieval systems evaluate citation confidence, meaning how confident the AI is that a page is authoritative on the topic it is being asked about. A page that addresses the primary topic but leaves adjacent concepts unaddressed forces the AI to cross-reference multiple sources before it can construct a complete answer. A page that addresses the primary topic and its conceptually adjacent concepts in the same document increases retrieval confidence and citation probability.
Entity co-occurrence is the mechanism. When a page about information gain also correctly addresses E-E-A-T, entity density, query fan-out, and topical authority, those entities occur in proximity to each other. AI knowledge graphs interpret co-occurring entities as evidence of genuine subject matter expertise. A page that mentions only the primary topic keyword without its semantic neighbours signals narrow or shallow coverage to the retrieval system, even if the primary topic is covered at depth.
Topical completeness signals work at two levels. At the page level, every H2 section should cover its sub-topic thoroughly enough that it could stand as a short post independently. At the cluster level, the relationship between your pillar page and its cluster posts creates a semantic map that AI systems interpret as topical authority at domain scale. A single well-written post is a citable document. A coherent cluster of well-written posts on related topics is a citable authority.
The practical process: before finalising any post outline, list the ten concepts most semantically adjacent to your primary topic. Identify which you address directly and which you leave out. For each concept left out, ask whether its absence weakens the page’s ability to answer the primary question completely. If it does, either add it to the post or ensure it is addressed in a linked cluster with a clear internal link from this page.
Semantic completeness does not mean covering everything. It means covering everything a knowledgeable reader would expect to see addressed by someone who genuinely understands the topic. The test is not ‘have I mentioned this concept’ but ‘have I addressed it with enough depth that an AI reading this page would consider my coverage of it authoritative.’
How Redot applies information gain in practice
Every piece of content Redot Global publishes for clients goes through a pre-writing information gain audit before a single word of body copy is written. The audit answers four questions.
First: what does this content know that no other published content knows? If the answer is nothing, the brief is sent back for revision. Generic briefs produce generic content. The audit forces the content owner to identify the proprietary insight before writing begins.
Second: what specific data, case study outcomes, or first-person observations will this post contain that cannot be found elsewhere? The answer to this question becomes the fact-blocks that anchor the post’s citation potential.
Third: what is the core answer this post delivers, and is that answer in the first paragraph of every section? BLUF is applied at the brief stage. The outline specifies the opening sentence of each H2 before the draft begins.
Fourth: what are the five follow-up questions a reader would ask after reading this post, and does the post address them? If not, those answers are added before the draft is considered complete. This is the semantic completeness audit applied at the brief level.
This process is why the content cluster you are reading now is structured the way it is. Each post delivers a specific dimension of the framework at exhaustive depth, linking to the others for adjacent dimensions, and together they constitute a complete technical brief for building a citation-visible digital presence in 2026.

Head of Digital Marketing, Redot Global
Kasun Asiri is a Digital Marketing Strategist with over 15 years of experience delivering high-impact digital growth initiatives across global markets. At Redot Global, he plays a key role in planning and executing performance-driven campaigns for international brands, consistently achieving measurable results through advanced SEO, Google Ads, and integrated digital visibility strategies. With deep expertise at the intersection of marketing, technology, and data, he specialises in building scalable growth systems powered by data science and AI-driven automation, transforming traditional marketing into efficient, data-driven frameworks designed to drive sustainable business growth. His work is defined by analytical thinking, strategic execution, and a commitment to delivering performance-focused solutions that align with business goals and long-term success.


