


Before engineering for AI citation, you need to understand the mechanism by which AI systems select their sources. Most content advice skips this step. The result is generic recommendations that do not address the actual selection criteria.
The dominant architecture behind AI search systems is Retrieval-Augmented Generation (RAG). RAG works in two phases. In the retrieval phase, the AI system queries a vector database or a search index to identify documents that are semantically relevant to the user’s query. In the generation phase, the language model reads the retrieved documents and synthesises a response, citing the sources it draws from.
Your content must survive the retrieval phase before it can ever appear in the generation phase. Retrieval is not the same as ranking. A page can rank well in traditional organic search and fail to be retrieved by an AI system because the content does not meet the structural and semantic requirements that retrieval algorithms apply.
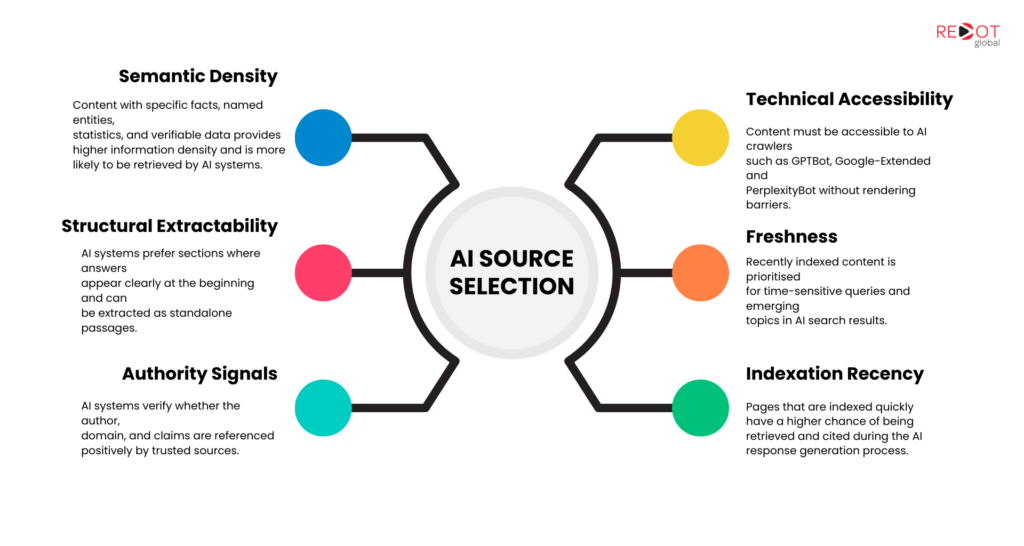
AI retrieval systems filter candidate documents against several criteria before they are passed to the generation model:
- Semantic density: How much specific, factual information is packed into the content. Vague explanatory content scores poorly. Content with named entities, verifiable statistics, specific processes, and declarative factual statements scores highly.
- Structural extractability: Whether the content’s answers can be lifted as standalone passages. A 400-word paragraph with a conclusion buried at the end is harder to extract than a section that opens with its core claim followed by supporting evidence.
- Authority signal verification: Whether the source domain, the author entity, and the content itself are referenced positively by other authoritative sources in the training data and live index. AI systems effectively run an authority check before selection.
- Technical accessibility: Whether AI crawlers (GPTBot, Google-Extended, PerplexityBot, ClaudeBot) can access, render, and parse the content. Content behind JavaScript rendering gaps, slow servers, or blocked crawlers simply does not exist to these systems.
- Freshness and indexation recency: AI search systems prioritise recently indexed content for time-sensitive queries. A page that takes two weeks to be indexed after publication has already missed the citation window for that news cycle.
Research published in the GEO benchmark study quantified the impact of content engineering on AI retrieval rates. Adding verifiable statistics, authoritative citations, and quotable declarative sentences increased a source’s visibility share in AI-generated responses by up to 40 percent compared to equivalent content lacking these structural signals.

Generative Engine Optimisation is the practice of structuring content so that large language models select it during the retrieval phase of their response generation workflow. The central concept is information gain: the degree to which your content adds new, verifiable, and specific information to the body of knowledge on a topic that no other source provides in the same form.
LLMs are trained to avoid redundant data. When a retrieval system evaluates ten pieces of content on the same topic, it selects the ones that offer the highest density of unique, verifiable information. Generic explainer content that restates publicly known definitions is the least likely to be selected. First-person documented expertise, proprietary data, and specific technical claims backed by verifiable evidence are the most likely to be selected.
Layer 2: Answer Engine Optimisation (AEO)
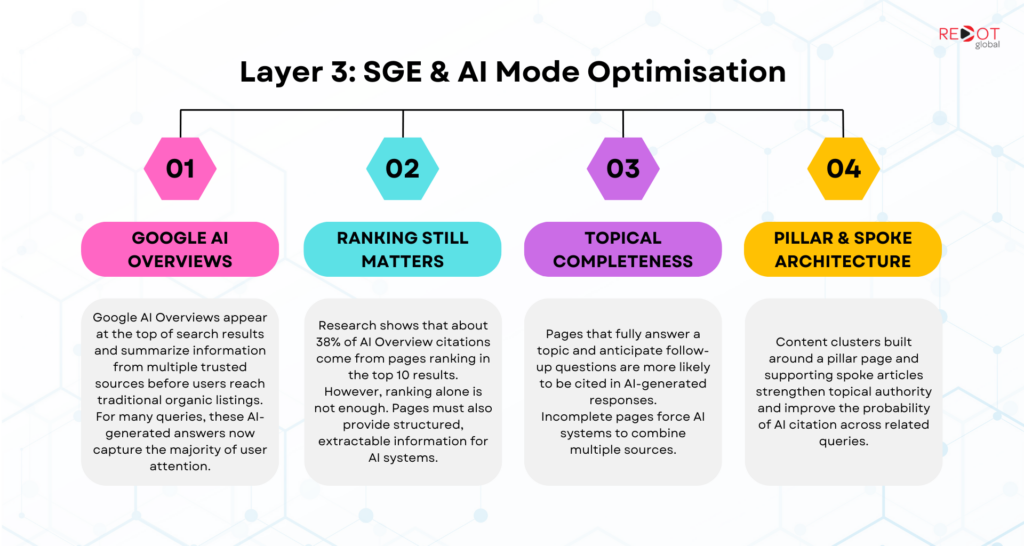
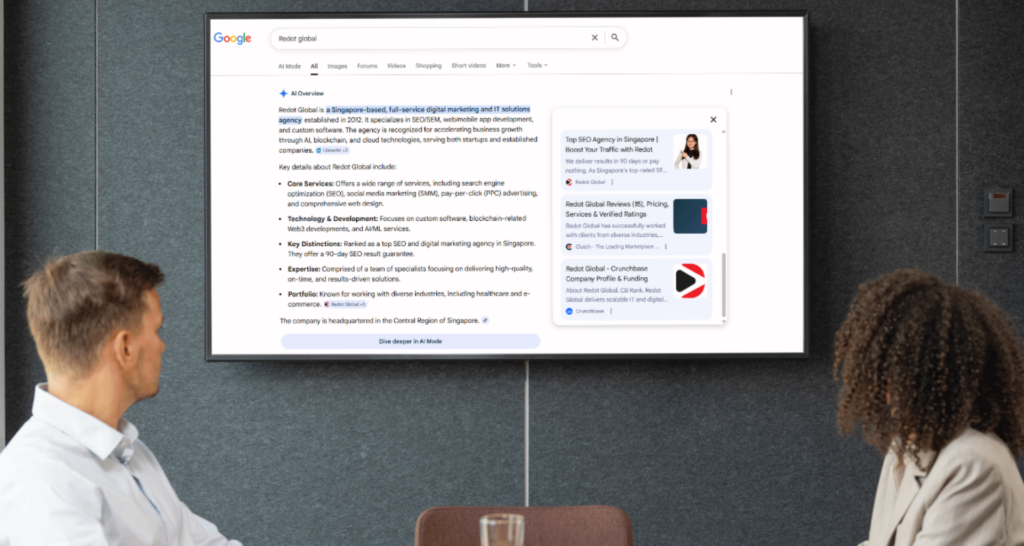
Google’s Search Generative Experience, now fully deployed as AI Mode and surfaced through AI Overviews on standard search results, represents the most commercially critical citation channel for Singapore businesses. Unlike Perplexity or ChatGPT, which operate as separate platforms, Google AI Overviews appear directly above the organic results on queries where hundreds of millions of searches per day occur.
The citation mechanics for Google AI Mode are more tightly coupled to traditional SEO signals than other AI platforms. Research by Ahrefs, updated in early 2026 across 863,000 keywords and 4 million AI Overview URLs, found that approximately 38 percent of AI Overview citations come from pages ranking in the top ten, down from 76 percent in mid-2025 as Google’s query fan-out process draws from a wider source pool. Ranking matters for AI Mode visibility in a way that it does not for ChatGPT or Perplexity citations. But ranking alone is insufficient. Pages that rank in the top ten but lack the structural requirements for AI extraction are bypassed in favour of lower-ranking pages that are better structured for citation.
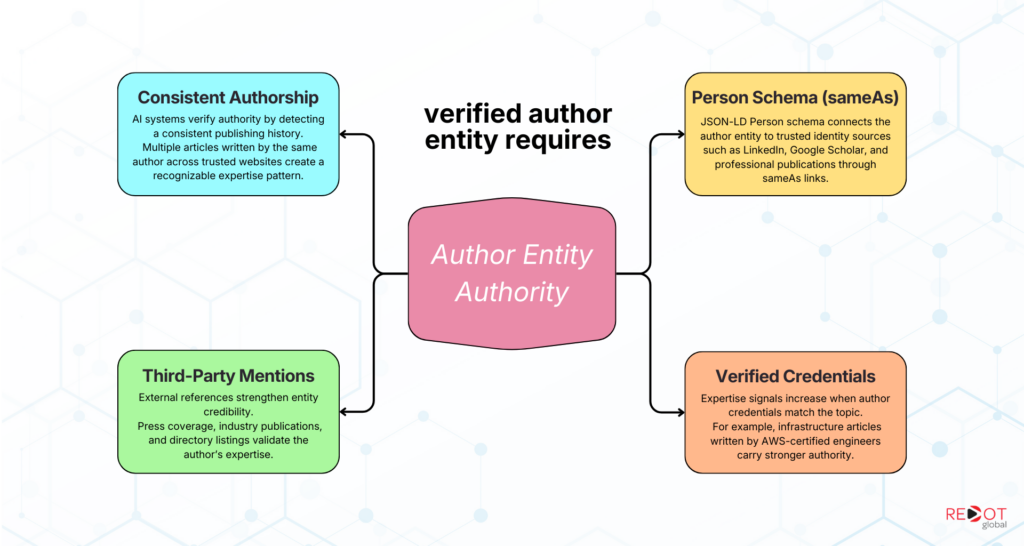
An author without a verified entity presence is a liability in AI citation selection. A verified author entity requires:
- A consistent authorship record: Multiple pieces of published content under the same name, across multiple authoritative domains where possible, creates a verifiable publication pattern that AI systems can identify.
- Person schema with sameAs links: JSON-LD Person markup on every author bio page linking to LinkedIn, Google Scholar, industry publication profiles, and other verifiable identity anchors. This is the technical mechanism that connects the author’s name on your site to the broader entity graph.
- Third-party entity mentions: Press coverage, conference speaking records, academic or industry publications, and professional directory listings that reference the author entity by name and connect them to a verifiable area of expertise.
- Credentials that match the topic domain: An article about AWS infrastructure carrying authorship from an AWS-certified engineer receives stronger authority signals than the same article published anonymously. The credential-topic alignment is part of what AI systems evaluate when verifying expertise claims.
AI systems do not weight all third-party sources equally. The sources most frequently reflected in AI citation patterns include:
- Major news and media publications: Coverage in publications that AI training datasets include at high weight. For Singapore businesses, the Business Times, The Straits Times, and regional tech publications like e27 and Tech in Asia carry significant weight in regional AI citation patterns.
- Reddit and community platforms: Reddit appears disproportionately in AI Overview citations and in LLM training data relative to its traditional SEO authority. A thread on r/singapore or r/SEO that mentions your brand in a specific, positive context contributes to entity recognition in ways that traditional link building does not.
- Industry certifications and partner directories: Google Partner directories, AWS Partner Network listings, and accreditation body references create verifiable entity connections between your brand and established institutions. These are citation signals that AI systems can verify directly.
- G2, Clutch, and structured review platforms: Review platforms with structured data are increasingly reflected in AI citation patterns for commercial queries. A well-maintained Clutch profile with specific service reviews contributes to the entity verification chain for queries like “best SEO agency Singapore.”
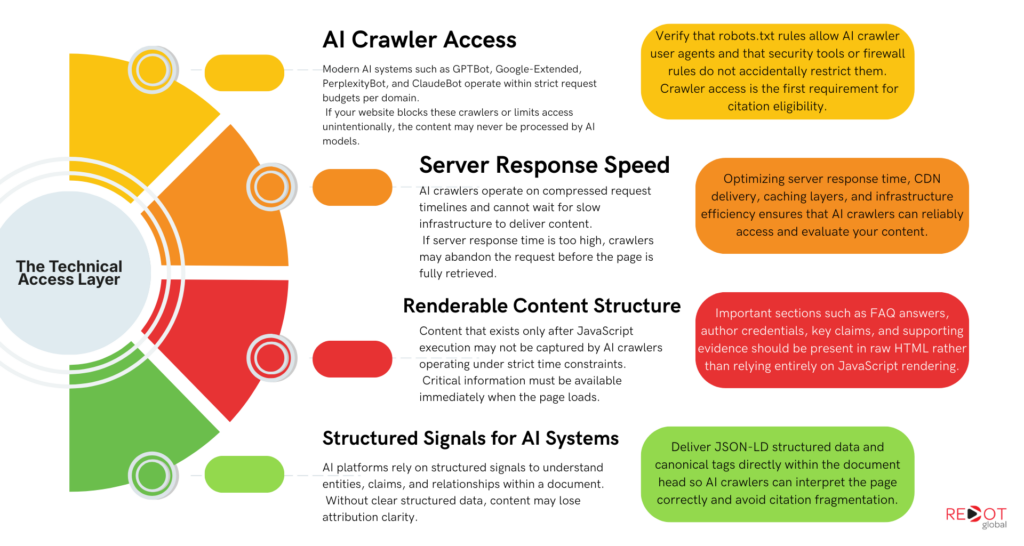
For content to be citation-eligible across all major AI platforms, the following technical conditions must be satisfied:
- Server response speed: AI crawlers operate on compressed request timelines. Slow server response risks crawler abandonment before content is received.
- Server-side rendering for critical content: Content that exists only after JavaScript execution is not guaranteed to be captured by AI crawlers operating on compressed timelines. FAQ sections, author bios, and structural claim paragraphs must exist in raw HTML.
- Crawl access for AI bot user agents: Verify that robots.txt does not inadvertently block GPTBot, Google-Extended, PerplexityBot, or ClaudeBot. Each has a distinct user agent string that must be explicitly permitted if your robots.txt uses a whitelist approach.
- Structured data in JSON-LD in the document head: Schema markup delivered via JavaScript injection may not be processed by AI crawlers in the same way it is processed by Googlebot’s secondary rendering wave.
Canonical tags in raw HTML: AI systems use canonical signals to avoid processing duplicate content. Canonicals delivered via JavaScript may not be honoured by all AI crawlers, leading to citation fragmentation across canonical and non-canonical URL variants.

A Citation Visibility Audit covers four diagnostic layers:
- AI citation sampling across platforms: Systematic querying of ChatGPT, Perplexity, Google AI Mode, and Bing Copilot using the target brand’s primary keywords and long-tail query variants. Citation presence, citation frequency, and citation context are recorded to establish a baseline visibility share.
- Crawler accessibility audit: Server log analysis for AI bot user agents (GPTBot, Google-Extended, PerplexityBot, ClaudeBot) to identify request failure rates, response time distributions, and content access gaps. Many businesses discover for the first time that significant crawler populations have been returning server errors or timeout responses for months.
- Content extractability audit: Evaluation of each high-priority page against fact-block architecture requirements, FAQ schema implementation, opening paragraph extractability, and entity density scoring. Pages are prioritised for rewriting based on citation gap size and commercial query alignment.
- Entity authority mapping: Review of Person schema implementation for all content authors, sameAs chain completeness, third-party entity mention inventory, and certification or partner directory listing status across Google, AWS, and industry-specific directories.

Co-Founder and Director, Redot Global
Suneth Silva is the Co-Founder and Director of Redot Global, a Singapore-based technology company specialising in AI-driven digital marketing, enterprise software development, and business automation. He leads strategy across technical SEO, performance marketing, and marketing analytics while overseeing engineering teams building cloud-native platforms and AI-enabled systems. His work integrates machine learning, LLM development, semantic search, and predictive analytics to deliver measurable growth for clients across hospitality, automotive, retail, finance, and government. With a background spanning software engineering, systems architecture, and applied AI, Suneth focuses on building end-to-end digital ecosystems that unify technology, data, and strategy.